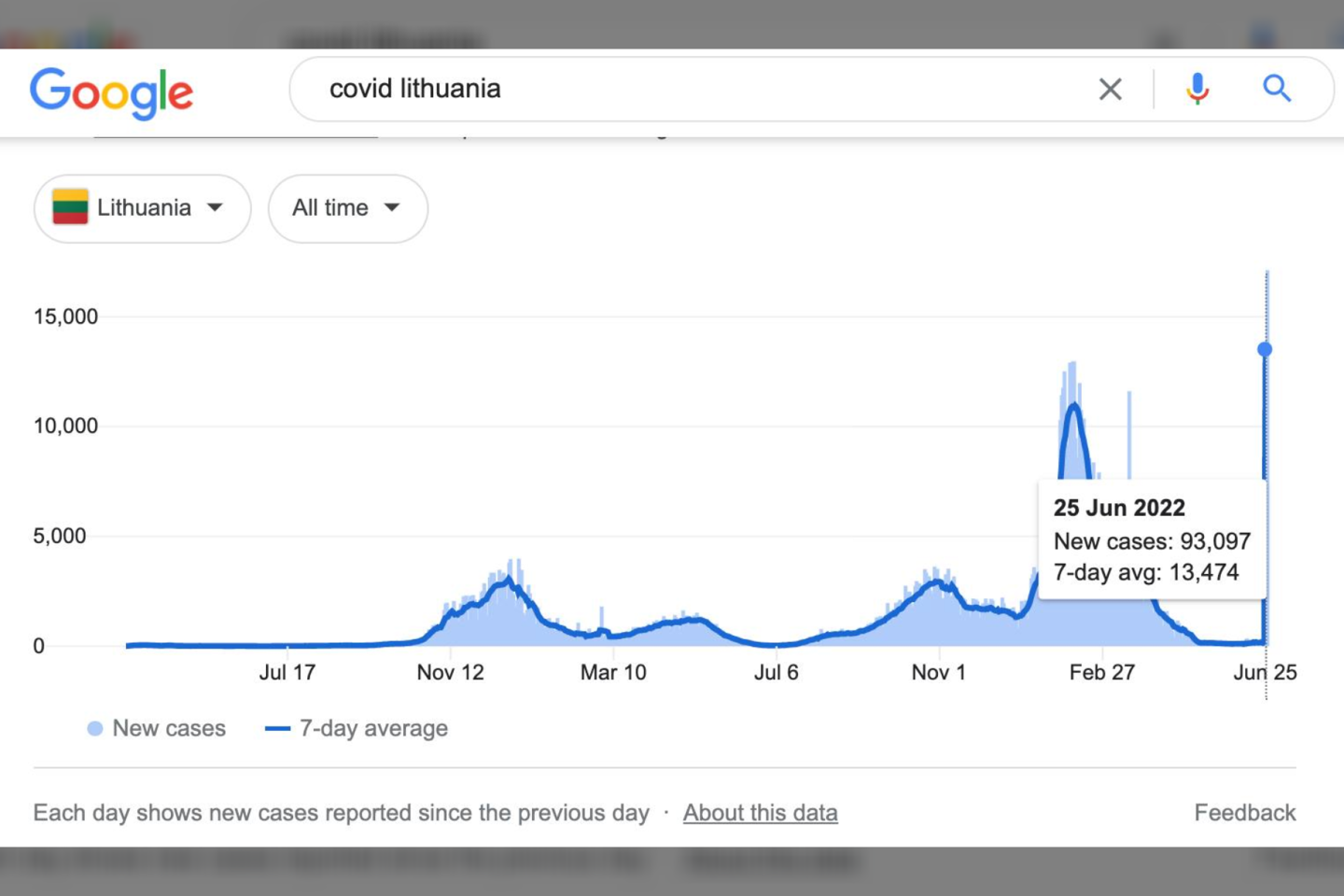
„Google" duomenis ima iš Johnso Hopkinso universiteto (JHU) švieslenčių, o JHU CSSE duomenų komanda tylomis tuos duomenis „scrapina“ (automatiškai surenka) iš mūsų lietuviškų švieslenčių (nežinodami, kad turime labai patogius atvirų duomenų failus). Kadangi neseniai keitėme švieslenčių struktūrą, jų „scrapinimo“ algoritmai nusimušė“, – rašoma Valstybės duomenų analitikos „Facebook“ paskyroje.
Bet, anot ekpertų, tai tik viena problemos dalis. Kita dalis – skirtingos abiejų pusių naudojamos datos priskyrimo įvykiui metodikos.
„Mes įvykiui priskiriame tą datą, kai tas įvykis įvyko (logiška, ar ne?). Tačiau JHU CSSE komanda įvykiui priskiria tą datą, kada jie apie tą įvykį sužinojo. Kai mes pradėjome skelbti naują rodiklį, įtraukiantį ir pirminius, ir antrinius, ir tretinius užsikrėtimus, JHU CSSE nusprendė naudoti būtent tą rodiklį, tačiau pagal savo metodiką visus istorinius pakartotinius užsikrėtimus (kurių yra beveik 100 tūkst.) priskyrė šeštadieniui“.
Ekspertų teigimu, dar šeštadienį dėl iškilusių nesklandumų pavyko susisiekti su JHU komanda ir surasti sprendimą – buvo nusiųstas sutvarkytas visų istorinių įvykių (užsikrėtimų, mirčių) archyvas, kurio pagrindu duomenys turi būti atnujinti. Deja, ekspertai mano, kad ši problema pasikartos ir ateityje.
„Toks yra jų pasirinkto datos priskyrimo įvykiui metodo trūkumas: visi duomenų papildymai „atgaline data“ priskiriami papildymo datai. Tačiau dabar bus daug lengviau viską ištaisyti, nes jau susipažinome“, – rašoma Valstybės duomenų analitikos „Facebook“ paskyroje.
